DeepWeightFlow: Re-Basined Flow Matching for Generating Neural Network Weights
A flow matching approach that operates directly in weight space to generate complete, high-performance neural network weights across MLP, ResNet, ViT, and BERT architectures. Accepted at ICLR 2026.


The lab’s paper “DeepWeightFlow: Re-Basined Flow Matching for Generating Neural Network Weights” has been accepted at the Thirteenth International Conference on Learning Representations (ICLR 2026). The work, led by Saumya Gupta and Scott Biggs with contributions from Maritz Laber, Zohair Shafi, Robin Walters, and Ayan Paul, introduces a generative model that produces complete weight sets for trained neural networks without fine-tuning, across a range of architectures and data modalities.
This post provides an accessible summary of the approach for a general research audience, followed by a more detailed technical description of the method, its design choices, and its empirical behavior.
A Semi-Technical Summary
Most of machine learning treats neural network training as an optimization problem: given a task and a dataset, find a single good set of weights. DeepWeightFlow takes a different view. It treats trained weights themselves as samples from a distribution, and learns a generative model over that distribution. Once trained, the model can sample many new, functioning networks for the target task in seconds, each of which performs comparably to a network trained from scratch.
Building such a generative model is difficult for three reasons. First, modern neural networks have tens of millions to hundreds of millions of parameters, which makes the weight space very high-dimensional. Second, neural networks have built-in symmetries: for example, permuting the hidden units of a multilayer perceptron and applying the inverse permutation in the next layer produces a functionally identical network. These symmetries mean that visually different weight configurations can encode the same function, complicating density estimation. Third, prior generative models either produce only partial weights, require post-hoc fine-tuning, or are slow to sample.
DeepWeightFlow addresses these issues with three design choices: it uses flow matching (rather than diffusion) to learn a vector field that transports Gaussian noise to the distribution of trained weights; it applies canonicalization techniques (Git Re-Basin for convolutional and feedforward architectures, TransFusion for transformers) to align training weights up to permutation symmetries; and it uses incremental and Dual Principal Component Analysis (PCA) as a simple linear dimensionality reduction step, avoiding the need for a separately trained autoencoder.
Empirically, networks sampled from DeepWeightFlow match the accuracy of the training networks on MNIST, Fashion-MNIST, CIFAR-10, STL-10, and the Yelp Review regression task, across MLPs, ResNet-18, ResNet-20, ViT-Small, and BERT-Base (118M parameters). The generated networks also transfer well to unseen datasets and can be produced in seconds per network on a single GPU, several orders of magnitude faster than diffusion-based alternatives.
Why Generate Neural Network Weights?
Treating collections of trained weights as a structured data modality opens up several downstream applications. Efficient generation of diverse, high-performance networks supports ensemble methods for uncertainty quantification, provides better initializations for transfer learning, and can accelerate neural architecture search. It also has implications for model editing, privacy-preserving model distribution, and rapid deployment of task-specific networks in distributed or resource-constrained settings.
The field has explored a range of approaches, including hypernetworks, variational autoencoders over weight latents, and diffusion models over partial or complete weight sets. Each has trade-offs. Several existing methods generate only a subset of the weights (typically batch normalization parameters) within a fixed pretrained backbone, which limits the diversity of the resulting networks. Others generate complete weights but require autoregressive decoding, layer-by-layer sampling, or post-generation fine-tuning. DeepWeightFlow aims to generate complete weights in a single pass, without conditioning on dataset characteristics or task descriptions, and without any fine-tuning of the sampled networks.
The DeepWeightFlow Pipeline
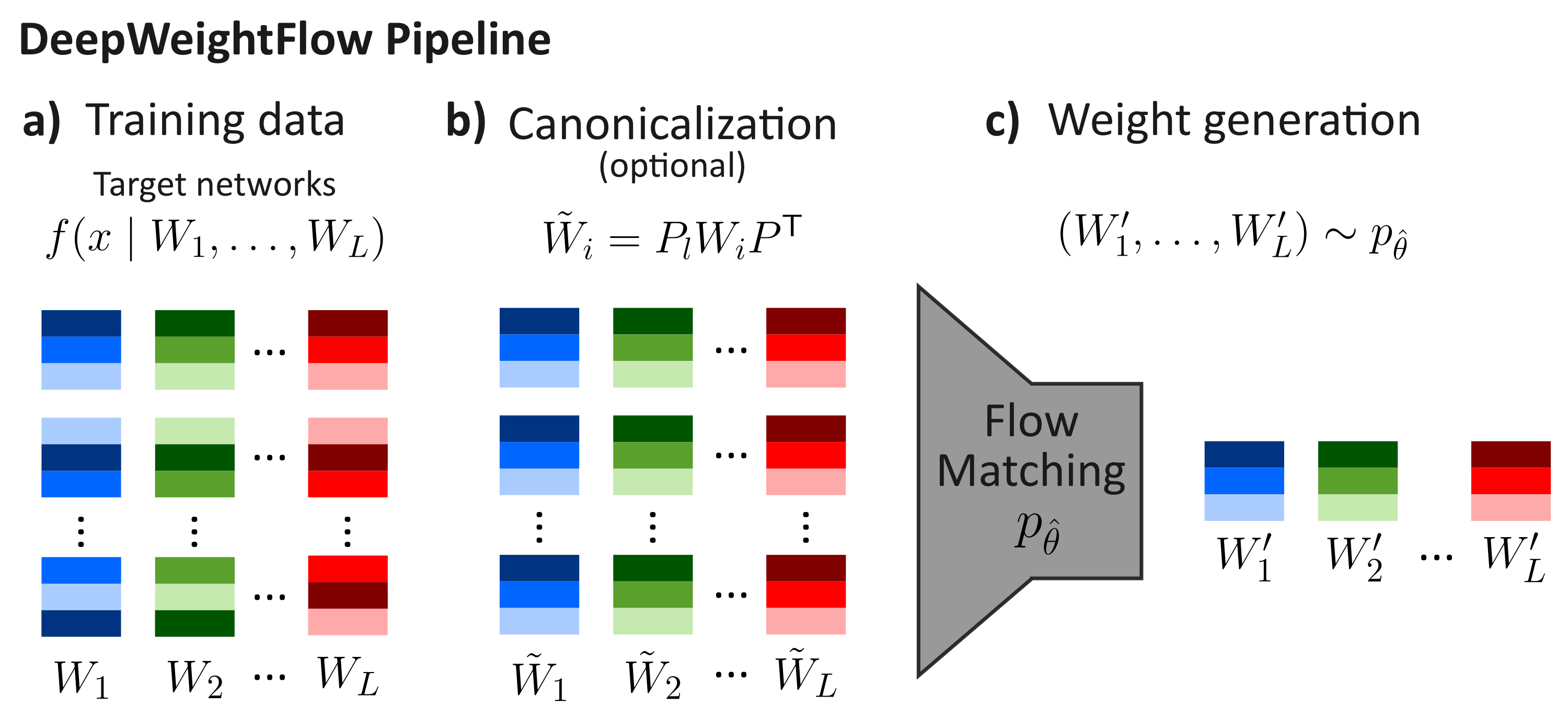
The pipeline has three stages. First, a dataset of trained networks is assembled. Each training point is the final set of weights from a complete training run; DeepWeightFlow does not use checkpoints from a single training trajectory, which prior work has shown can artificially reduce diversity. One hundred networks per task, each initialized with a distinct random seed, constitute a typical training set.
Second, the weights are optionally canonicalized. For MLPs and convolutional networks, Git Re-Basin is applied for one hundred iterations to align each network to a reference network by solving a sequence of linear assignment problems over the layerwise permutation matrices. For vision transformers, the TransFusion procedure is used: it first matches attention heads across networks by comparing the singular value spectra of their projection matrices, then aligns rows and columns within each head. Both procedures produce canonical representatives within each equivalence class of the permutation group, reducing the symmetry-induced multi-modality of the weight distribution.
Third, a flow matching model is trained to transport samples from a Gaussian source distribution to the distribution of canonicalized weights. At inference time, Gaussian noise is sampled and integrated through the learned vector field using a fourth-order Runge–Kutta solver to produce a new set of weights.
Flow Matching in Weight Space
Flow matching (Lipman et al., 2023) learns a time-dependent vector field vθ(x, t) that transports a source distribution p0 to a target distribution p1. Given samples x0 from the source and x1 from the target, the linear interpolant μt = (1 − t)x0 + tx1 defines a probability path with constant velocity ut = x1 − x0. The model is trained to regress on this velocity at time points sampled uniformly from the unit interval. Compared to diffusion, flow matching offers simpler training dynamics, faster sampling, and direct regression on the vector field, which scales well to high-dimensional targets.
In DeepWeightFlow, the vector field is parameterized by a simple MLP with GELU activations, layer normalization, and dropout. The flow hidden dimension dh is the primary capacity parameter and is varied from 32 to 1024 depending on the architecture being generated. The scalar time t is passed through a small embedding MLP and concatenated with the weight vector at each layer of the flow model. To stabilize training, small Gaussian perturbations are added to the interpolated points. Samples are generated by integrating the learned vector field from Gaussian noise using an RK4 solver with one hundred steps.
The choice of source distribution is important. The paper reports that a Gaussian source with standard deviation matching or slightly below the standard deviation of the target weight distribution consistently outperforms alternatives such as Kaiming initialization as a source, and that this sensitivity is most pronounced at low flow model capacity.
Canonicalization and Permutation Symmetry
Neural networks exhibit a rich class of symmetries that leave the encoded function invariant. For an MLP, joint permutations of the hidden units in adjacent layers preserve the function exactly. Convolutional networks exhibit analogous symmetries over channels, and transformers exhibit additional symmetries within and between attention heads. These symmetries induce a highly multi-modal loss surface and, by extension, a multi-modal weight distribution, which is difficult for a generative model to cover efficiently.
Three strategies have been explored in the weight-space learning literature to handle these symmetries: data augmentation, equivariant architectures, and canonicalization. DeepWeightFlow takes the canonicalization approach. Git Re-Basin reduces the problem of aligning two networks to a sum of bilinear assignment problems, which is NP-hard in general but well-approximated by a sequence of linear assignment problems solved with the Hungarian algorithm. TransFusion extends this idea to transformers through a two-stage procedure that first pairs attention heads using singular value spectra and then aligns rows and columns within each head.
The paper provides an empirical characterization of when canonicalization helps. At low flow model capacity, training on canonicalized weights produces ensembles with higher accuracy and lower variance than training on non-canonicalized weights. As capacity increases, the two approaches converge. For weight spaces of moderate dimension, canonicalization offers limited benefit, while for high-dimensional weight spaces such as those of ResNet-18 and ViT-Small, canonicalization yields measurable improvements at lower capacity, allowing smaller flow models to reach the performance of the training set.
Scaling with PCA
Training a flow model directly on the flattened weight vectors of a ResNet-18 (eleven million parameters) or a BERT-Base (one hundred eighteen million parameters) is not feasible on a single GPU without dimensionality reduction. DeepWeightFlow uses linear PCA as a preprocessing step, avoiding the need to train an autoencoder. For networks with tens of millions of parameters, incremental PCA is applied to the set of flattened weights, retaining 99 principal components (one fewer than the number of training networks, which upper-bounds the rank of the data matrix). After generation, the inverse PCA transform recovers weights in the original space.
For larger networks, the paper introduces a Dual PCA formulation that computes principal components via the eigendecomposition of the n × n Gram matrix rather than the d × d covariance matrix, where n is the number of training networks and d is the parameter count. This exploits the fact that the nonzero eigenvalues of XXT and XTX coincide. Combined with randomized SVD and streamed, micro-batched matrix accumulation, Dual PCA enables PCA on model collections whose full parameter matrices do not fit in memory. Using this approach, DeepWeightFlow scales to BERT-Base while keeping training and sampling times modest.
Batch Normalization Recalibration
Networks that contain batch normalization layers pose a distinctive challenge. The running mean and variance statistics of batch normalization layers are tied to the training data distribution and are not learned parameters in the gradient sense, so they are not reliably reproduced by a flow model trained on weight samples alone. The paper reports that directly transferring running statistics from a reference network yields poor performance, and that generated ResNet-18 networks without recalibration achieve near-chance accuracy.
The recalibration procedure recomputes running statistics by passing a small subset of the target dataset through the generated network with momentum updates disabled, incrementally accumulating per-channel means and variances. After recalibration, generated ResNet-18 networks recover accuracies comparable to the training set (approximately 93.5% on CIFAR-10, versus approximately 94.5% for the training networks). Layer normalization, which is permutation-invariant and does not maintain running statistics, does not require this step.
Empirical Results
The paper evaluates DeepWeightFlow on a range of architectures and tasks. On MNIST with a three-layer MLP, generated networks reach 96.17% accuracy with Git Re-Basin and 96.19% without, compared to 96.32% for the training networks. On CIFAR-10 with ResNet-18, generated networks reach 93.55% with Git Re-Basin and 93.47% without, compared to 94.45% for the training networks. On CIFAR-10 with ViT-Small-192, generated networks reach 83.07% with TransFusion and 82.58% without, compared to 83.30% for the training networks. On the Yelp Review regression task with BERT-Base (118M parameters), generated networks achieve a Spearman correlation of 0.7909, compared to 0.7902 for the training networks.
On transfer learning, ResNet-18 networks generated for CIFAR-10 transfer to STL-10 and SVHN without fine-tuning more effectively than randomly initialized networks and match the transfer performance of the original training networks. After five epochs of fine-tuning on STL-10, generated networks reach 84.63% accuracy, compared to 84.61% for training networks and 51.35% for random initialization. Comparable results are reported for transfer to CIFAR-100.
Diversity is assessed using the maximum intersection-over-union (mIoU) between the sets of misclassified examples for pairs of networks. Generated networks show mIoU values that indicate genuine diversity relative to the training set and are distinct from training networks with small additive Gaussian noise. The paper also reports Jensen–Shannon, Wasserstein, and nearest-neighbor distances supporting the same conclusion.
Training and Sampling Efficiency
DeepWeightFlow is considerably faster than diffusion-based alternatives for complete weight generation. Training times range from approximately three minutes for ResNet-18 to approximately twenty-one minutes for ViT-Small on a single NVIDIA A100. Sampling is on the order of one to two seconds per network for ResNet-18 and ViT-Small, and approximately twenty-two seconds per network for BERT-Base. For comparison, the paper notes that RPG, a recurrent diffusion model for complete weight generation, can take on the order of hours to generate a comparable set of networks.
Limitations and Future Work
The paper is explicit about limitations. Multi-class and multi-architecture conditional generation, explored in the appendix, does not yet produce networks with competitive accuracy; the authors attribute this to the fragmentation of the weight distribution when multiple architectures or datasets are combined. The compatibility of DeepWeightFlow with model distillation, low-rank approximations, and sparsity remains to be explored. The relative merits of canonicalization, equivariant architectures, and data augmentation for learning in deep weight spaces remain open questions. Extension to the O(1B) parameter regime is identified as a natural next step, building on the Dual PCA infrastructure developed in this work.
Code and Paper
The full paper is available on OpenReview and arXiv, and the code is released at github.com/NNeuralDynamics/DeepWeightFlow. The training datasets will be made available on request.